
Scalability and Elasticity
Now, let’s talk about Pulsar’s scalability and elasticity. Scalability refers to the ability to handle large volumes of data, data streams, etc. Elasticity means you can grow or shrink resources quickly to adapt to workload changes This can save infrastructure costs by avoiding over-provisioning. Some data-streaming platforms like Kafka and Pulsar can scale very well. But Pulsar is both scalable and elastic. Let’s walk through three examples of Pulsar’s scalability and elasticity.
Large Volume of Messages in a Topic or Variable Topic Throughput
The bottleneck in data processing often lies with the consumer rather than the broker or the producer. The consumer not only needs to read the data but also process it, and this processing can be resource-intensive, making it the common bottleneck.
We already discussed the ability to create a message queue. This is completed using one of the four subscription types: shared subscription.
With Kafka, the number of consumers is closely tied to the number of topic partitions. Increasing the number of consumers would require increasing the number of topic partitions, a time-consuming process that requires a data rebalance across partitions.
With Pulsar, the number of consumers can be increased without any need for data rebalancing. Alternately, if the message throughput decreases, the number of consumers can be easily decreased saving infrastructure costs.
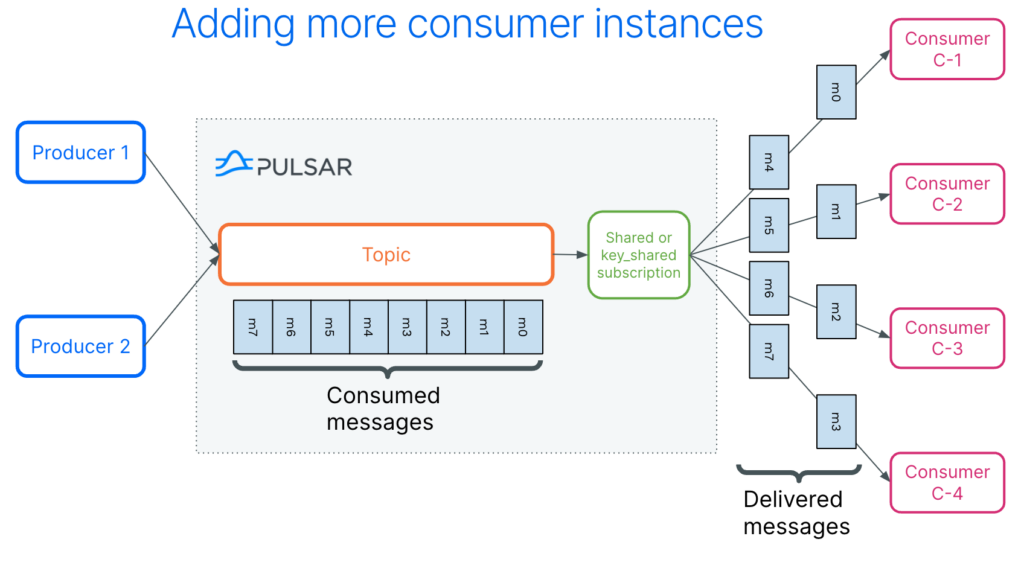
If some level of message ordering is needed, a key_shared subscription can be used. When a key is added to a message, a key_shared subscription guarantees all messages with a given key will be sent to the same consumer.
Large Volume of Topics or Client Connections
Pulsar brokers are responsible for managing client connections, receiving messages from producers and dispersing messages to consumers through subscriptions. To understand how Pulsar can quickly scale up or down this serving layer without requiring rebalancing, let’s discuss the unique architecture of Pulsar.
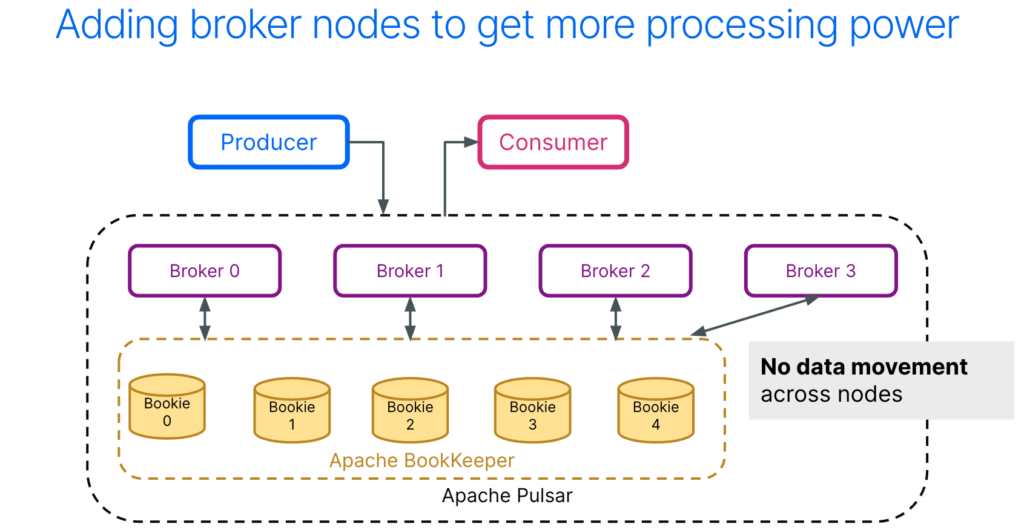
Pulsar’s architecture is more sophisticated than other platforms. The brokers are responsible for managing all the communication and the processing of the topics. Broker nodes are stateless: they don’t store data except caches for efficiency.
In contrast, the bookies (Apache BookKeeper) nodes are responsible for storage. They have state and are where the messages are stored.
When the volume of data or number of client connections requires more resources, the number of brokers can be increased. In the example to the left, Broker 3 is added to increase the capacity of the serving layer. Broker 3 will start serving producers and consumers and is able to access data on any of the bookies immediately. No data rebalancing is needed.
If the overall data volume through your cluster decreases, the number of brokers can be easily decreased without moving data across bookies. This can be completed manually or through broker auto-scaling. This architecture also leads to the resiliency of Pulsar in case of a broker crash.
Storage Capacity
Finally, let’s discuss Pulsar’s ability to scale it’s storage layer.
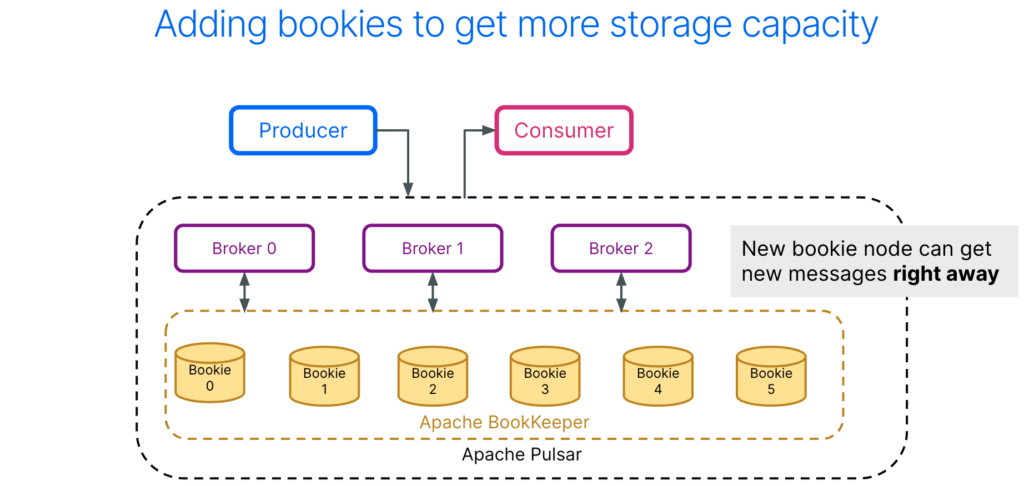
When we need to store more data, we can add more disk space per bookie or add more bookies.
In the example to the left, Bookie 5 is added to the cluster. As soon as you add Bookie 5, all brokers become aware of it and it’s eligible for storing new messages immediately. This architecture allows us to scale the serving and storage layers independently.
We will discuss more in the next section how Pulsar ensures data resiliency inside the storage layer.
For more information on Pulsar’s architecture, visit the Pulsar documentation here.